The White House Just Said What SOC Teams Have Known for Years
The White House just pivoted: human-speed cybersecurity has reached its ceiling. Discover why the shift to agentic AI is no longer optional and how Legion is bridging the gap between machine-speed threats and human-scale defense.


I spent a long time staring at screens that couldn't keep up. Not because the analysts weren't good, but because the volume, the speed, the sheer relentlessness of what we were defending against had already outpaced the model. Tier 1 is working a queue. Tier 2 is doing the same thing, slower with more context. Tier 3 is getting pulled into fires before they finish the last one. Humans are trying to move at machine speed. It never worked. We just found ways to cope with it not working.
On March 6th, the White House said it out loud. It states directly that the administration will "rapidly adopt and promote agentic AI in ways that securely scale network defense." It calls for AI-powered cybersecurity solutions to defend federal networks and deter intrusions at scale. It frames the cyber workforce not as the primary defense mechanism, but as the strategic asset that designs and deploys the systems that do the actual defending.
That is not subtle. That is a pivot.
I've seen a lot of strategy documents come and go. Most of them describe the problem correctly and then propose solutions that require the same broken model to execute them. More analysts. More tools. More compliance frameworks that generate reports nobody reads. This one is different in a specific way. It acknowledges that human-speed defense has a ceiling, and the adversary has already blown past it.
This matters operationally. Not because government mandates translate directly to enterprise practice, but because the logic behind the mandate is undeniable and most organizations are about two or three incidents away from being forced to confront it themselves.
Here is what I actually read in that document when I strip away the political framing:
Threat actors are using AI to accelerate attack timelines and broaden their operational surface area. The gap between when something happens and when a human analyst understands what happened is widening. That gap is where organizations get compromised. The strategy is essentially acknowledging that the only viable response to AI-accelerated offense is AI-accelerated defense. Not AI-assisted. Not AI-augmented. AI that acts.
That is exactly what we built Legion to do.
Not because we read the strategy. Because we lived through the alternative. I've watched skilled analysts spend the first forty minutes of an investigation just gathering context. Pulling logs from one tool, cross-referencing with another, chasing an IP through three different platforms before they can even form a hypothesis. That is not a people problem. That is a workflow problem. And it compounds at scale until your senior analysts are doing glorified data retrieval and your tier 1 analysts are drowning in volume they were never equipped to handle alone.
Legion treats that problem directly. It captures how experienced analysts actually investigate, the sequences, the correlations, the judgment calls, and runs those workflows autonomously at the speed the threat environment requires. Not replacing the analyst, but removing the friction that slows the analyst. Campaign hunting, alert triage, IOC blocking, CVE impact assessment across your entire environment, running while your team focuses on what actually requires human judgment.
The strategy also makes a point worth taking seriously. Deploying autonomous AI in your environment without understanding what it's doing is not security. It's a different kind of exposure. The document calls for securing the entire AI technology stack, and that is not bureaucratic language. That is operational reality. Any organization rushing to adopt agentic capabilities without visibility into how those agents operate and what they can access has traded one risk for another.
The teams I respect are the ones asking both questions at the same time. How do we move at machine speed? And how do we maintain accountability over the systems doing it?
The strategy just told you where the industry is going. The question is whether your operations are positioned to keep pace with it, or whether you're still trying to scale a model that was already failing before the AI arms race began.
I know which answer I kept seeing at 3 am.
Legion Security is Now Available on Google Cloud Marketplace
Security operations were built around human investigators. Skilled analysts, working manually across dozens of tools, piecing together evidence, making judgment calls, closing cases. But as alert volumes outpaced human capacity, institutional knowledge became a bottleneck, and the complexity of the modern enterprise made scaling impossible. The industry responded with more headcount, more tools, more automation. None of it solved the fundamental problem.
Legion introduces a different operating model entirely.
What Legion Does
Legion observes how your analysts operate when running real investigations, learning your organizational context, tools, past cases, playbooks, runbooks and all other tribal knowledge in order to understand what an optimal investigation looks like for your environment. This is then turned into an easily editable and audible workflow which can be automated when you’re ready. Powered by Google Cloud's Gemini models, each workflow is executed by AI agents that reason through the evidence and provide a verdict and even remediate. This is all accomplished with no manual playbook writing or need to document predefined rules.
But legion goes well beyond workflow creation. As Legion builds trust in its performance, teams can choose to keep a human in the loop to approve every decision or have Legion operate fully autonomously reducing MTTR eliminating MTTA, allowing analysts to focus on more novel investigations that are becoming more and more common in the world of AI.
Memory: The Compounding Advantage
Every investigation Legion conducts makes it smarter. A persistent memory layer continuously captures context from previous cases, your SOC knowledge base, and direct analyst feedback, feeding all of it back into future investigations and decisions. Institutional knowledge that once lived in the heads of your most experienced analysts becomes a permanent, improving organizational asset. The more Legion works, the better it gets. That's not a feature. That's a compounding strategic advantage.
Zero Integrations. Immediate Value.
Most security automation platforms fail at the same hurdle: integrations. Enterprises face months of API work, custom connectors, and professional services before anything runs in production, or are forced to adopt entirely new tools and processes, something most complex enterprises simply can't do.
Legion operates natively in the browser, which means it works across your entire security stack, from threat intel platforms to legacy internal tools, without any API configuration. If your analysts can open it in a browser, Legion can learn from it, generate workflows from it, and execute investigations through it.
Proven Results at Scale
The impact Legion delivers isn't theoretical:
As the head of Security at Virgin Money put it, Legion is “like evolving from handcrafted systems to precision manufacturing aligned to our flow (except) faster, repeatable and secure”.
Legion works with the worlds largest enterprises and delivers strong results:
- A large insurance organization automated 24,000 investigations and cut mean time to respond from 20 minutes to 2 minutes.
- WELL Health Technologies reduced investigation times by 81%, allowing existing analysts to handle significantly higher alert volumes without additional headcount.
- The University of Tulsa cut investigation times in half, enabling their team to overcome capacity limits with the staff they already had.
Across deployments, Legion reduces mean time to investigate by up to 85% and response times by up to 90%.
Built on Google Cloud
Legion's integration with Google Cloud goes deeper than the Marketplace listing. The platform runs on Google Cloud infrastructure and leverages Gemini models to power its AI reasoning, combining Legion's browser-native architecture with Google Cloud's security, scale, and model quality.
For organizations already invested in Google Cloud and Google SecOps, Legion extends that ecosystem directly into the analyst workflow.
Who It's For
Legion is purpose-built for enterprise security operations teams, CISOs, VPs of Information Security, SOC Directors, and Security Operations Managers at organizations running in-house SOCs. If your team is dealing with any of the following, Legion was built for you:
- Alert volumes that have outpaced your team's capacity
- Analyst burnout from manual, repetitive investigation work
- Institutional knowledge that walks out the door when senior analysts do
- Automation gaps caused by complex integration requirements
Available Now on Google Cloud Marketplace
Legion Security is available today on Google Cloud Marketplace, allowing customers to apply their spend toward their annual Google contract and simplify procurement. For security teams ready to move beyond the limits of traditional operations, this is where that transformation begins.

Legion is officially on the Google Cloud Marketplace.

Abstract & Data Summary
We gathered and manually annotated a dataset of 196 hard triage decisions from real-world security investigations, covering a wide range of outcomes, including benign, malicious, and false positives. After cleaning the dataset by removing mock runs and cases with missing information or incorrect workflow execution, the remaining 163 examples were grouped into use case categories to form a high-quality cohort. We then evaluated LLMs on the dataset overall and per use-case category and found that Gemini 3 Pro performs best overall, though the best LLM varies by use case category.
Model performance by use case category:
If you’d like to understand our full research methodology, read on.
*Note: since this blog was authored, several new model families have been released. While the results have remained broadly stable, particularly among the best and worst performers, updated research may be required for a nuanced understanding of the performance differences amongst the rest.
Data Collection
The dataset was constructed from security investigations from eight US-based customers.The evaluation is conducted in a secure, federated way, without mixing customer data, only reporting summary statistics from each customer tenant.
To create a challenging evaluation, we over-weighted cases in which the analyst dis-agreed with the model - so the error rate is inflated here.
The investigations were conducted automatically according to predefined, customer-specific workflows, each of which contained at least one triage decision node. A triage decision node is a decision point within a workflow, where an LLM chooses a decision from among a list of provided decision options, given the information that was gathered in the workflow up until that point.
At each decision node, the LLM used in production selected a classification decision from a list of workflow-specific decision options and provided the reasoning for its decision, based on a summary of the steps completed until that point in the investigation.
For each investigation containing at least one decision node, we collected the following information from production session logs:
- A summary of the workflow steps up until the decision node, including tool name, step description, and step outputs
- Organization-specific knowledge, written by the customer and containing a title, description, and data
- The set of available decision options at the decision node
- The model's selected decision in production, as well as the reasoning and detailed reasoning for the decision
- The decision option selected by the customer
- Feedback text written by the customer for the decision
Here is an example workflow diagram:
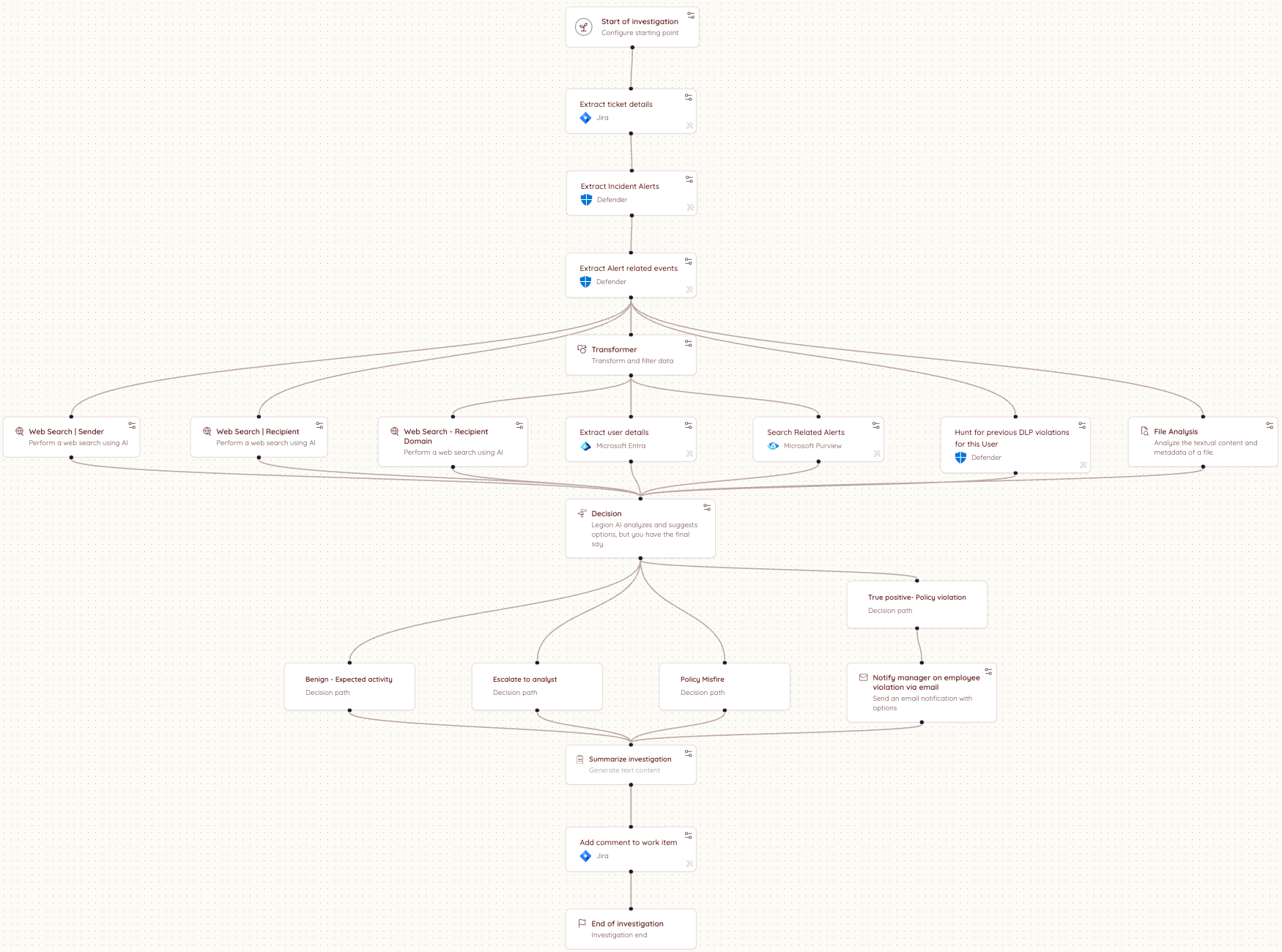
Quality Control
An expert cybersecurity analyst annotated the 196 decision examples with reasoning tags to explain the production and customer decisions, and label whether disagreements are explained by an analyst-error, mistaken reasoning by the AI or missing data / steps in the workflow.
Examples tagged with "Workflow ran correctly but missing information" or "Workflow ran incorrectly" were removed from the dataset. Two additional examples with the use case titled "Workshop" were removed, as these were mock runs. For the remaining examples, the workflow ran correctly and was not missing information.
Triage Decision Distribution
By Label
Across the filtered dataset, the workflows contained 27 distinct normalized decision labels, which we grouped into the following buckets: False Positive, True Positive, Requires Review, and Other. The distribution of the labels is shown below:
The final evaluation dataset contains data from eight customers. The table below shows the number of annotated decision examples per customer and the tools used in each environment.
Use Case Distribution
We consolidated the use cases into 3 categories to consolidate our findings. Below is the map from the consolidated categories to the original use cases, as well as the distribution of the dataset over the consolidated categories.
Confusion Matrix
Below is a confusion matrix between the expert analyst annotations and the recommendations our system makes. We prompt the models to be careful and escalate when they are not sure.
Results
Over all use cases (including those without a use case name), Gemini 3 Pro had the highest performance at 74.8%, with GPT-4.1 and Opus 4.5 tied for second.
Phishing Results:
On the phishing use cases, Gemini 3 Pro performed the best, followed by Opus 4.5.
Account Takeover Results:
Sonnet 4 and GPT-4.1 were tied for best on the account takeover use cases.
Network Results:
Opus 4.5 and GPT-4.1 were tied for best on the network use cases.
Conclusion & Recommendation
We gathered and annotated 163 triage decisions from real-world security investigations. We characterized the use case distribution, and grouped the use cases according to common categories. We then benchmarked large language models across each use case category and the full dataset. We found that Gemini 3 Pro performs best overall. Per use case category, Gemini 3 Pro gives the best performance on phishing, Sonnet 4 and GPT-4.1 are tied for best on account takeover, and Opus 4.5 and GPT-4.1 are tied for best on network. Based on our results, we recommend that security teams test models for different scenarios to find the solution that works best for their use case, different models are good at different things and the only way to know which model works best for your use-cases it to run formal evaluation - or, you can trust us! Our research team in Legion is constantly evaluating new models and improvements to our triage pipelines.

We benchmarked leading LLMs on 163 real-world security triage decisions across phishing, account takeover, and network use cases. See which models performed best and why the answer depends on your use case

The security industry spent years debating when attackers would gain capabilities once out of reach — nation-state-level offensive tooling, zero-day discovery at scale, exploits built and iterated in minutes.
That gap was real. And it gave organizations the impression that the decision about which AI to bring into security operations, and how to do it right, could wait until the picture was clearer.
Mythos ended that assumption.
Not because of the model's size or strength, but because by the time Anthropic announced it, Mythos had already found thousands of high-severity vulnerabilities across every major operating system and browser in use today, without being told where to look. The decision not to release is the signal everyone was looking for.
That changes the implementation question. It was never acceptable to deploy AI badly in the SOC. Now it's not acceptable to deploy it slowly either. The organizations that will come out on top in the next 12 months are the ones that move fast and get it right, and most of the industry is about to discover that those aren't the same thing.
Level set: defenders have always been behind
The average breach lifecycle was already 258 days before AI-assisted attacks became the norm. This has nothing to do with the capabilities of analysts. Human-speed defense against machine-speed offense was always a losing equation.
Mythos-class models will almost certainly expand this breach lifecycle delta.
Most Implementations Are Getting It Wrong
87% of organizations experienced an AI-driven cyberattack in the past year. Security teams know they need AI. Most are already moving. But most implementations are failing for the same reason, and it is not the technology. It is a missing critical datapoint.
You. The context that shapes your business.
Most AI SOC tools treat every organization as interchangeable. They integrate with your SIEM, your EDR, your threat intel platforms, and assume that is enough. It is not. What determines whether AI actually works in your environment has nothing to do with the list of integrations. It is the organizational context that no integration can capture.
How is your organization structured? Where does data actually live versus where it is supposed to live? Who owns what, and how does that map to investigation and response when something goes wrong? How do escalation paths work in practice, not on paper? And critically, how do you enable the business without interrupting it?
The difference shows up clearly in practice. A heavily regulated enterprise running investigations across proprietary internal platforms looks nothing like a technology company. The organizational context that shapes every investigation, every escalation decision, and every response action is invisible to a system that only sees tool outputs.
Closing that gap is the foundational requirement that most implementations skip entirely.
Org Context Is Not a One-Time Setup
This is where most implementations fail, even when they start well.
Organizational context is not a configuration you complete on day one. Your organization is a living thing. Teams change. Tools get added. Processes evolve. New subsidiaries appear. Risk posture shifts with every acquisition, every regulatory update, every new product line the business launches.
An AI system that ingested your context six months ago and stopped learning is already drifting from your reality. It is making decisions based on an organization that no longer exists.
The right model is not a one-off ingestion. It is a continuous learning system that stays embedded in how your organization actually operates, tracks how investigations unfold, incorporates analyst feedback, and updates its understanding as your environment changes.
Not a snapshot.
A persistent model of your specific organization that evolves with it.
What Good Implementation Actually Looks Like
First, AI systems needs to understand how your organization actually operates. Not how it is documented, but how investigations really unfold, where data actually lives, and how decisions get made under pressure. The gap between what is written down and what actually happens is where most AI systems fail.
Second, that understanding cannot be static. Organizations change constantly. New teams, new tools, new processes, new risk priorities. Any system that relies on a snapshot of your environment will drift from reality and degrade over time. The AI working in your environment needs to keep learning it, not just learn it once.
Third, it needs to operate within that context, not around it. Producing technically correct outputs is not enough. The system needs to produce outcomes that are actionable within your organization as it exists today. That means working within your existing workflows, tools, and constraints without asking you to change how you operate to accommodate it.
That is the standard. Systems built around this model behave differently from the start. They do not ask organizations to adapt to them. They adapt to the organization. That distinction is where most implementations succeed or fail, and it is where the industry is slowly converging.
The Only Durable Path
The organizations getting AI right in the SOC aren't the ones with the longest integration lists or the biggest models. They're the ones that treated organizational context as the foundation rather than the afterthought, and built systems that keep learning their environment rather than freezing it in place on day one.
That is a harder implementation. It requires more from the vendor and more from the buyer. But Mythos made the timeline for getting there non-negotiable. The organizations that move fast on the wrong implementation will spend the next year rebuilding. The ones that move slowly on the right one will spend it exposed. The only durable path is moving quickly on the version that actually holds up. Systems built on continuous organizational context, deployed now rather than after the next incident, force the question.
The gap that used to buy time for deliberation is gone. What's left is the quality of the decision you make in its absence.
.png)
Mythos ended the debate on whether AI belongs in the SOC. The new question is how to deploy it right and why organizational context is the foundation most implementations skip.
