Resources


Introducing Legion AI Investigator: AI that reasons where playbooks can't. Define the goal, set the guardrails, and let it investigate across your tools — no integrations required.

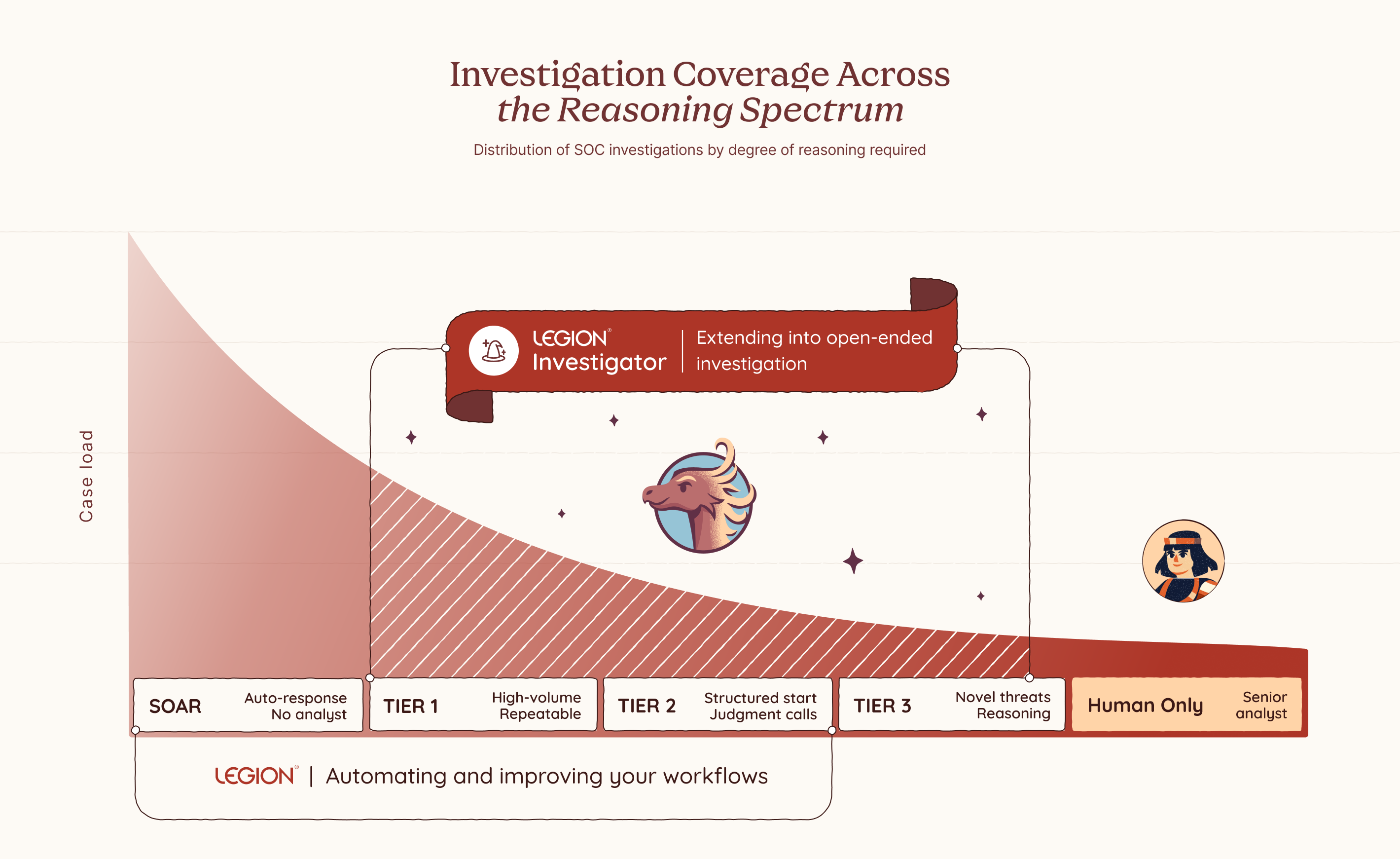
SOC investigations range widely. Some are highly repeatable: every step defined, every decision documented. These work well and can be fully automated. But some investigations eventually reach a point where that breaks down: where the next step depends on what you just found, and the judgment and intuition to know what it means.
You can see it clearly the moment you try to write it down. Some processes flow neatly from start to finish. But as soon as you move into more complex investigations, the cracks appear. You find yourself pulled into a spiral of edge cases, tool variations, and fallback paths. You add branches. Then branches on branches. And after all that effort, you almost always end up in the same place: where no rule applies, and only judgment, reasoning and intuition can take you further.
The Part You Can Never Quite Capture
SOC investigations don't all look the same. Some are fully deterministic: a user notification when an outgoing email gets blocked, no reasoning required. For these, consistency matters. The same steps, the same outcome, every time. Others are the opposite: novel threats with no fixed path, no known pattern, where only experience, intuition, and judgment can tell you what to do next. And many fall somewhere in between, where you start with structure and hit a point where judgment has to take over.
But even those flows have a ceiling. Take a phishing investigation. You can document the triage steps pretty cleanly: check the sender, analyze the headers, detonate the attachment, check the URLs. That part is routine and capturable. But the moment you find something suspicious, the investigation shifts. Now you need to reason about scope: is this part of a campaign, and who else was hit? That question has no fixed answer. You might search for other emails with the same subject, but any decent campaign will vary the lures across targets, changing subjects, sender names, and payload links to evade detection. You cannot match on a single field and call it done. You need to iterate: follow one thread, see what it reveals, adjust your search, go again. You are reading the environment in real time, making judgment calls at every step based on what the last one uncovered.
Those judgment points show up on every shift, on every alert that goes beyond the routine. Someone has to reason through them in the moment, with whatever context they have, under whatever pressure exists right now. Until 3am. Until a less experienced analyst picks it up. Until alert volume means there simply isn't time to think it through properly.
That reasoning is not pre-programmed. It emerges from the finding itself. It is what a senior analyst does instinctively, and until now there has been no way to replicate it at scale. Legion Investigator is built for that moment.
Your Environment. Your Logic. Your Investigator.
Legion Investigator is a goal-oriented AI agent that sits inside your investigation workflow at exactly the moments where reasoning takes over from execution, extending Legion's coverage across the full spectrum of SOC investigations, from fully deterministic workflows to complex open-ended investigations. You define its goal, you choose which tools and actions it is permitted to use, and you decide where it acts autonomously and where it checks in first.
Which category a given investigation falls into is sometimes obvious. But often it is a deliberate choice, one that should be yours to make based on your team's needs, your risk tolerance, and how much consistency versus flexibility the situation calls for. Where on that spectrum each investigation runs is yours to decide. Every boundary is one you set in advance and can trust will be respected. This is what makes Investigator the kind of AI enterprises can actually adopt: not just powerful, but designed from the ground up to operate within your constraints, your processes, and your level of trust.
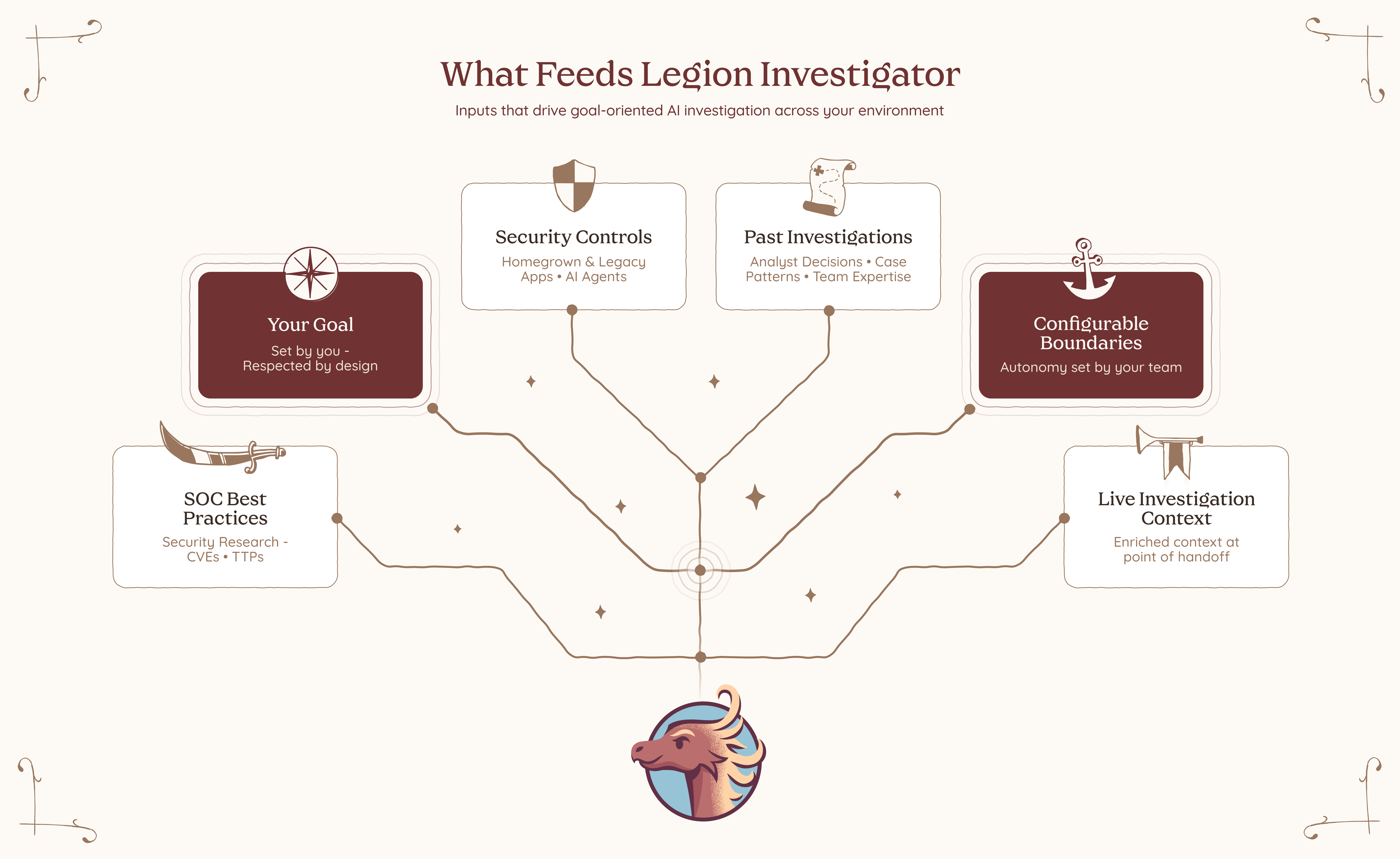
Most AI SOC tools bring their own model of how investigations should work. Legion Investigator learns from how yours actually do. It builds its understanding from your team's recorded investigation sessions, the decisions they make, the paths they take, and the patterns that emerge across real cases in your environment. Over time, Legion builds a structured knowledge base specific to your organization, capturing your processes, your tooling, and your team's accumulated expertise. That knowledge is not just stored. It is actively used to improve your captured workflows and feeds directly into how Investigator reasons, prioritizes, and investigates.
And when we say your tools, we mean all of them. Legion Investigator works the way your analysts work, through the browser, with no integrations and no APIs required. Your SIEM, your EDR, your threat intelligence platforms, your homegrown applications, your legacy dashboards, your on-prem and cloud environments. You don’t rebuild your stack to fit the tool. The tool fits your stack.
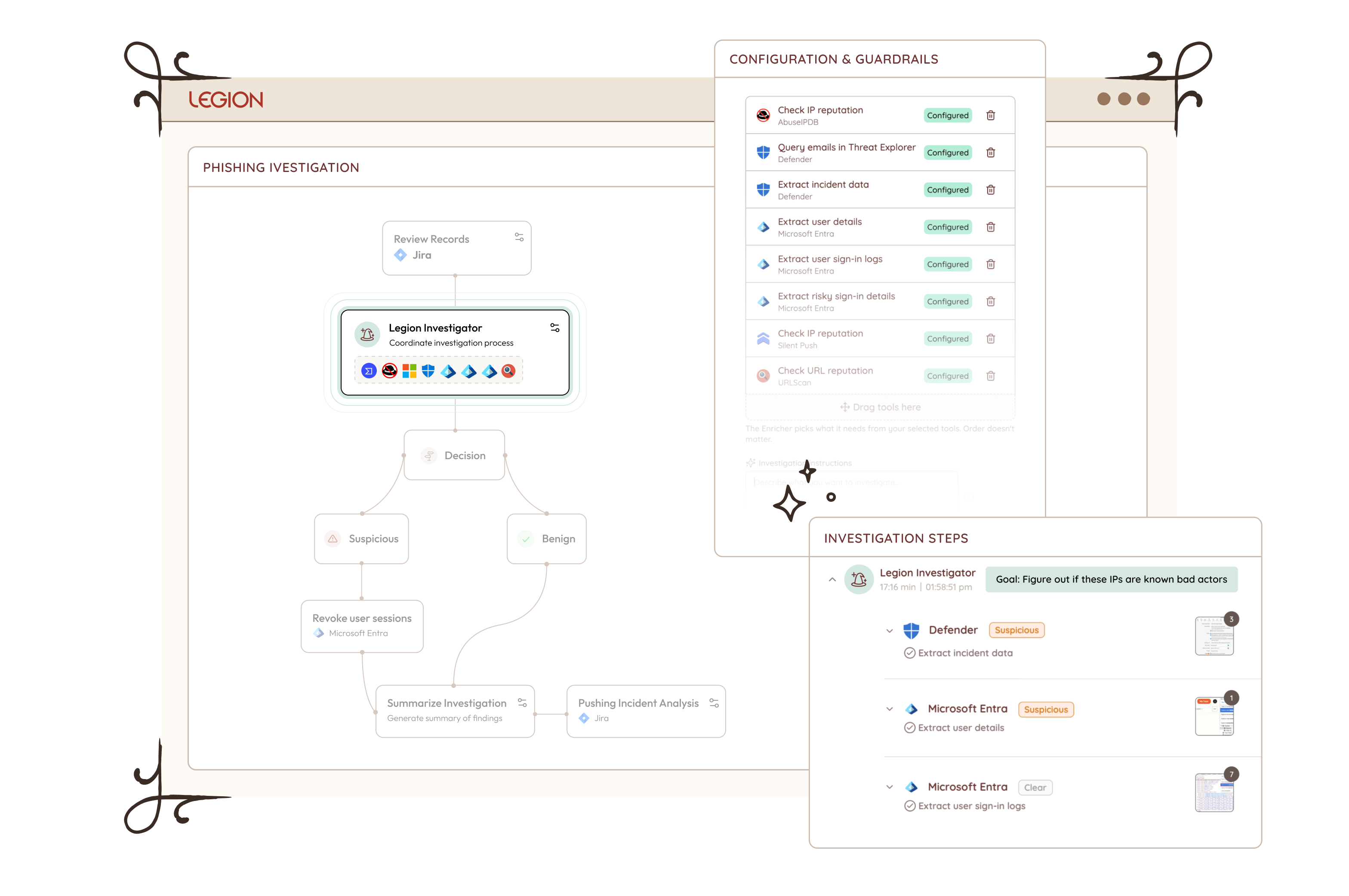
The way it works reflects how investigations actually flow. An investigation might start in your SIEM with a set of routine queries, structured, reliable, repeatable. But when it reaches one of those decision points, you hand off to an Investigator with a goal: find the scope of breach, enrich the full context of what we have so far, identify what else was impacted across endpoints and cloud assets.
The Investigator takes that goal and works toward achieving it. It invokes the relevant tools, interprets what comes back, recalculates what to do next, and invokes again. It keeps going, step by step, until the goal is met. Not a single tool call with a result handed back to you. A full reasoning loop that runs until the work is done, across your security tools, your homegrown applications, and any AI agents already running in your environment. Investigator acts as the orchestrator, pulling in whatever is needed to get there.
Multiple Investigators can work together across a single investigation. One handles enrichment. Another determines scope of breach. A third drives containment based on what was actually found, not what was anticipated when the playbook was written.
And because trust matters, Investigator operates within guardrails. It works only with the tools and actions it’s been given permission to use. For anything higher risk, it asks before acting. You stay in control by setting the boundaries in advance and knowing they’ll be respected.
What This Changes
Legion Investigator opens up three things that weren't possible before.
Pick up where deterministic processes end
For investigations where you have structured steps, you can now embed an Investigator at exactly the points where structure runs out. The routine parts stay routine.The investigator reasons further, and by the time you step in, the groundwork is already done.
Handle your long tail of alerts
For the long tail of investigations where you never had a well-defined flow to begin with, you can now hand them off end to end. The Investigator handles enrichment before you even open the case, drives containment the moment scope is confirmed, and picks up every judgment point in between. Give the Investigator the goal, set the guardrails, and let it run. No playbook required.
Every investigation, regardless of how well-defined it is, can now be handled with the depth of your best analyst, on every alert, on every shift. And for the first time, you control where on that spectrum each investigation runs. More structure where consistency matters. More autonomy where judgment, experience, and intuition are required. The balance is yours to set, and yours to change.
This is not about replacing analysts. It never was. There will always be moments that require human judgment, experience, and instinct, and no AI should pretend otherwise. What changes is everything around those moments. The analyst becomes the commander: setting goals, defining boundaries, sending investigators out into the environment to gather, reason, and report back. The calls that matter stay with you. The work that surrounds them no longer has to. Not because we built a smarter AI. Because we built one that learned from you.
SOC investigations range widely. Some are highly repeatable: every step defined, every decision documented. These work well and can be fully automated. But some investigations eventually reach a point where that breaks down: where the next step depends on what you just found, and the judgment and intuition to know what it means.
You can see it clearly the moment you try to write it down. Some processes flow neatly from start to finish. But as soon as you move into more complex investigations, the cracks appear. You find yourself pulled into a spiral of edge cases, tool variations, and fallback paths. You add branches. Then branches on branches. And after all that effort, you almost always end up in the same place: where no rule applies, and only judgment, reasoning and intuition can take you further.
The Part You Can Never Quite Capture
SOC investigations don't all look the same. Some are fully deterministic: a user notification when an outgoing email gets blocked, no reasoning required. For these, consistency matters. The same steps, the same outcome, every time. Others are the opposite: novel threats with no fixed path, no known pattern, where only experience, intuition, and judgment can tell you what to do next. And many fall somewhere in between, where you start with structure and hit a point where judgment has to take over.
But even those flows have a ceiling. Take a phishing investigation. You can document the triage steps pretty cleanly: check the sender, analyze the headers, detonate the attachment, check the URLs. That part is routine and capturable. But the moment you find something suspicious, the investigation shifts. Now you need to reason about scope: is this part of a campaign, and who else was hit? That question has no fixed answer. You might search for other emails with the same subject, but any decent campaign will vary the lures across targets, changing subjects, sender names, and payload links to evade detection. You cannot match on a single field and call it done. You need to iterate: follow one thread, see what it reveals, adjust your search, go again. You are reading the environment in real time, making judgment calls at every step based on what the last one uncovered.
Those judgment points show up on every shift, on every alert that goes beyond the routine. Someone has to reason through them in the moment, with whatever context they have, under whatever pressure exists right now. Until 3am. Until a less experienced analyst picks it up. Until alert volume means there simply isn't time to think it through properly.
That reasoning is not pre-programmed. It emerges from the finding itself. It is what a senior analyst does instinctively, and until now there has been no way to replicate it at scale. Legion Investigator is built for that moment.
Your Environment. Your Logic. Your Investigator.
Legion Investigator is a goal-oriented AI agent that sits inside your investigation workflow at exactly the moments where reasoning takes over from execution, extending Legion's coverage across the full spectrum of SOC investigations, from fully deterministic workflows to complex open-ended investigations. You define its goal, you choose which tools and actions it is permitted to use, and you decide where it acts autonomously and where it checks in first.
Which category a given investigation falls into is sometimes obvious. But often it is a deliberate choice, one that should be yours to make based on your team's needs, your risk tolerance, and how much consistency versus flexibility the situation calls for. Where on that spectrum each investigation runs is yours to decide. Every boundary is one you set in advance and can trust will be respected. This is what makes Investigator the kind of AI enterprises can actually adopt: not just powerful, but designed from the ground up to operate within your constraints, your processes, and your level of trust.
Most AI SOC tools bring their own model of how investigations should work. Legion Investigator learns from how yours actually do. It builds its understanding from your team's recorded investigation sessions, the decisions they make, the paths they take, and the patterns that emerge across real cases in your environment. Over time, Legion builds a structured knowledge base specific to your organization, capturing your processes, your tooling, and your team's accumulated expertise. That knowledge is not just stored. It is actively used to improve your captured workflows and feeds directly into how Investigator reasons, prioritizes, and investigates.
And when we say your tools, we mean all of them. Legion Investigator works the way your analysts work, through the browser, with no integrations and no APIs required. Your SIEM, your EDR, your threat intelligence platforms, your homegrown applications, your legacy dashboards, your on-prem and cloud environments. You don’t rebuild your stack to fit the tool. The tool fits your stack.
The way it works reflects how investigations actually flow. An investigation might start in your SIEM with a set of routine queries, structured, reliable, repeatable. But when it reaches one of those decision points, you hand off to an Investigator with a goal: find the scope of breach, enrich the full context of what we have so far, identify what else was impacted across endpoints and cloud assets.
The Investigator takes that goal and works toward achieving it. It invokes the relevant tools, interprets what comes back, recalculates what to do next, and invokes again. It keeps going, step by step, until the goal is met. Not a single tool call with a result handed back to you. A full reasoning loop that runs until the work is done, across your security tools, your homegrown applications, and any AI agents already running in your environment. Investigator acts as the orchestrator, pulling in whatever is needed to get there.
Multiple Investigators can work together across a single investigation. One handles enrichment. Another determines scope of breach. A third drives containment based on what was actually found, not what was anticipated when the playbook was written.
And because trust matters, Investigator operates within guardrails. It works only with the tools and actions it’s been given permission to use. For anything higher risk, it asks before acting. You stay in control by setting the boundaries in advance and knowing they’ll be respected.
What This Changes
Legion Investigator opens up three things that weren't possible before.
Pick up where deterministic processes end
For investigations where you have structured steps, you can now embed an Investigator at exactly the points where structure runs out. The routine parts stay routine.The investigator reasons further, and by the time you step in, the groundwork is already done.
Handle your long tail of alerts
For the long tail of investigations where you never had a well-defined flow to begin with, you can now hand them off end to end. The Investigator handles enrichment before you even open the case, drives containment the moment scope is confirmed, and picks up every judgment point in between. Give the Investigator the goal, set the guardrails, and let it run. No playbook required.
Every investigation, regardless of how well-defined it is, can now be handled with the depth of your best analyst, on every alert, on every shift. And for the first time, you control where on that spectrum each investigation runs. More structure where consistency matters. More autonomy where judgment, experience, and intuition are required. The balance is yours to set, and yours to change.
This is not about replacing analysts. It never was. There will always be moments that require human judgment, experience, and instinct, and no AI should pretend otherwise. What changes is everything around those moments. The analyst becomes the commander: setting goals, defining boundaries, sending investigators out into the environment to gather, reason, and report back. The calls that matter stay with you. The work that surrounds them no longer has to. Not because we built a smarter AI. Because we built one that learned from you.
Introducing Legion AI Investigator: AI that reasons where playbooks can't. Define the goal, set the guardrails, and let it investigate across your tools — no integrations required.
I spent a long time staring at screens that couldn't keep up. Not because the analysts weren't good, but because the volume, the speed, the sheer relentlessness of what we were defending against had already outpaced the model. Tier 1 is working a queue. Tier 2 is doing the same thing, slower with more context. Tier 3 is getting pulled into fires before they finish the last one. Humans are trying to move at machine speed. It never worked. We just found ways to cope with it not working.
On March 6th, the White House said it out loud. It states directly that the administration will "rapidly adopt and promote agentic AI in ways that securely scale network defense." It calls for AI-powered cybersecurity solutions to defend federal networks and deter intrusions at scale. It frames the cyber workforce not as the primary defense mechanism, but as the strategic asset that designs and deploys the systems that do the actual defending.
That is not subtle. That is a pivot.
I've seen a lot of strategy documents come and go. Most of them describe the problem correctly and then propose solutions that require the same broken model to execute them. More analysts. More tools. More compliance frameworks that generate reports nobody reads. This one is different in a specific way. It acknowledges that human-speed defense has a ceiling, and the adversary has already blown past it.
This matters operationally. Not because government mandates translate directly to enterprise practice, but because the logic behind the mandate is undeniable and most organizations are about two or three incidents away from being forced to confront it themselves.
Here is what I actually read in that document when I strip away the political framing:
Threat actors are using AI to accelerate attack timelines and broaden their operational surface area. The gap between when something happens and when a human analyst understands what happened is widening. That gap is where organizations get compromised. The strategy is essentially acknowledging that the only viable response to AI-accelerated offense is AI-accelerated defense. Not AI-assisted. Not AI-augmented. AI that acts.
That is exactly what we built Legion to do.
Not because we read the strategy. Because we lived through the alternative. I've watched skilled analysts spend the first forty minutes of an investigation just gathering context. Pulling logs from one tool, cross-referencing with another, chasing an IP through three different platforms before they can even form a hypothesis. That is not a people problem. That is a workflow problem. And it compounds at scale until your senior analysts are doing glorified data retrieval and your tier 1 analysts are drowning in volume they were never equipped to handle alone.
Legion treats that problem directly. It captures how experienced analysts actually investigate, the sequences, the correlations, the judgment calls, and runs those workflows autonomously at the speed the threat environment requires. Not replacing the analyst, but removing the friction that slows the analyst. Campaign hunting, alert triage, IOC blocking, CVE impact assessment across your entire environment, running while your team focuses on what actually requires human judgment.
The strategy also makes a point worth taking seriously. Deploying autonomous AI in your environment without understanding what it's doing is not security. It's a different kind of exposure. The document calls for securing the entire AI technology stack, and that is not bureaucratic language. That is operational reality. Any organization rushing to adopt agentic capabilities without visibility into how those agents operate and what they can access has traded one risk for another.
The teams I respect are the ones asking both questions at the same time. How do we move at machine speed? And how do we maintain accountability over the systems doing it?
The strategy just told you where the industry is going. The question is whether your operations are positioned to keep pace with it, or whether you're still trying to scale a model that was already failing before the AI arms race began.
I know which answer I kept seeing at 3 am.

The White House just pivoted: human-speed cybersecurity has reached its ceiling. Discover why the shift to agentic AI is no longer optional and how Legion is bridging the gap between machine-speed threats and human-scale defense.

Security leaders often talk about the cost of hiring analysts. Salaries, benefits, training budgets, and a recruiter or two. Those numbers are simple to track, so they tend to dominate planning conversations. The reality inside every SOC is very different. The real costs do not show up neatly in a spreadsheet. They accumulate in the gaps between processes, in the repetitive tasks analysts cannot avoid, and in the institutional drag created when people burn out or walk out the door.
Most SOCs are not struggling with a talent shortage. They are struggling with talent waste. Skilled people spend too much time on work that is beneath their capabilities. The hard truth is that this is a design problem, not a staffing problem. Until SOCs address it head-on, the cycle repeats itself: more hiring, more turnover, more loss of knowledge, more missed opportunities.
This is the part of the SOC budget most leaders still underestimate.
The Real Cost of Hiring and Ramp-Up
Hiring an analyst feels like progress. It also comes with costs that rarely get accounted for. The first few months of a new hire can be more expensive than the hire itself. Senior analysts are pulled away from active investigations to train newcomers. Work slows down. Processes become inconsistent.
One customer summarized the issue clearly: “Most of our onboarding time goes into walking new analysts through the same basic steps. If we could guide them through those workflows with Legion, our team could focus their time on real investigations.”
When experienced analysts spend their days teaching repetitive steps instead of improving detection quality or strengthening defenses, the SOC loses far more than money. It loses momentum. And momentum is what allows a team to stay ahead of attackers.
Repetitive, Boring Work Creates Predictable Burnout
Tier 1 and Tier 2 analysts often do not quit because the mission is uninspiring. They quit because the tasks are. Every SOC leader knows this, but very few have solved it. The daily flood of low complexity alerts, routine enrichment steps, and copy-and-paste investigations grinds people down.
Burnout is not a mystery. It is the predictable result of asking talented people to repeat the same low-value tasks.
When people leave, you lose more than a seat. You lose context, intuition, and the fundamental knowledge that comes from long-term exposure to your environment. Hiring someone new does not replace that.
The Opportunity Cost That Quietly Slows Every SOC
In many SOCs, highly skilled analysts spend their time on tasks that could have been automated five years ago. This is the least visible and most expensive form of waste. It does not show up as a line item in the budget. It shows up in everything the team is not doing.
A customer of ours captured the thinking many teams share:

When analysts are busy with manual steps, they are not threat hunting, tuning detection rules, studying new adversary behaviors, or improving processes.
This is how SOCs fall behind. Not because the analysts are incapable, but because their time is misallocated. Attackers innovate faster than teams can adjust. That gap widens when analysts are stuck doing repetitive tasks rather than strategic work.
A Better Path: Give Analysts the Power to Automate Their Own Work
SOCs have tried to fix these problems by hiring more people. That has not worked. They have tried building automation through security engineering teams. That added new bottlenecks. They have tried to hire outsourced help, it created inconsistency, while decreasing visibility.
What works, and what the most forward-thinking SOCs are now adopting, is a different approach. Automation belongs with the analysts, not with developers or specialized engineers.
One analyst put it simply: “We are bringing the ability to automate to the analyst. It is about self-empowerment.”
When analysts can automate the steps they repeat every day, they stop depending on engineering cycles. They stop waiting for API integrations. They no longer need someone with Python skills to script the basics.
This shift changes the entire rhythm of the SOC.
The Role of AI SOC in Quality and Consistency
For years, automation required an engineering mindset. Tools demanded scripting, manual API work, and knowledge of multiple integrations. Analysts were forced to rely on others. As a result, automation never became widespread.
That reality is changing. Browser-based tools like Legion can now capture workflows directly from the analyst’s actions. No API configuration. No scripts. No custom requests. Analysts can drag and drop steps, adjust logic, or describe edits in natural language.
A customer of ours said it plainly:

This matters because it removes the old automation bottleneck. It lets analysts fix their own inefficiencies as soon as they see them.
Turning Senior Expertise into a Force Multiplier
A SOC becomes stronger when its best analysts teach others how they think. Historically, this type of knowledge transfer was slow and informal. New hires watched over shoulders. Senior staff answered endless questions. Training varied widely depending on who happened to be available.
Now teams record their own best work and turn it into reusable, repeatable workflows.
One analyst described the shift: “Senior people record their workflows and junior people run them. You share expertise and bring everyone to the level of your top people.”
Another added: “It is a useful training tool because junior folks can see what the investigation looks like and understand the decision-making in each step.”
This approach does more than speed up onboarding. It locks valuable expertise into the system so it can be reused at any time.
Real Results: More Output With the Team You Already Have
When repetitive work is automated, analysts suddenly have time. This is where the economic impact becomes impossible to ignore.
One organization measured the difference:

Another organization brought an entire outsourced SOC back in-house. Their automation results gave them enough capacity and quality improvements to cancel a seven-figure managed services contract. The CISO wanted consistent quality. The SOC manager wanted efficiency. Legion delivered both.
The manager became the hero of the story because he did not ask for more people. He made better use of the ones he already had.
Where to Begin If You Want to Reduce These Hidden Costs
You do not need a complete transformation plan to get started. Most SOCs can begin reducing waste immediately by focusing on a few straightforward steps.
1. Identify high-frequency workflows: Look for anything repetitive, especially tasks that happen dozens of times per day.
2. Ask analysts to document their steps: This becomes the foundation for automation and reveals inconsistencies. We do this at Legion through a simple recording process.
3. Build automation for the repetitive use cases: Let analysts automate on their own without developers. This creates speed and value for repetitive work.
4. Track real metrics: MTTI/MTTR, MTTA (Acknowledgement), onboarding time (a time to value metric), and workflow usage
5. Encourage a culture of sharing: When people share workflows, the entire team improves faster. There are almost always steps that differ between analysts.
Small shifts compound quickly. Capacity increases. Quality rises. Analysts feel more ownership and less drain.
The SOC of the Future Makes Better Use of Human Talent
The SOCs that succeed over the next decade will not be the ones that hire the most people. They will be the ones who make the smartest use of the people they already have.
When you eliminate the hidden costs, you unlock the real value of your team. Human judgment, intuition, and creativity become the focus again. That is the work analysts want to do. And it is the work that actually strengthens your defenses.

Most SOCs are not struggling with a talent shortage. They are struggling with talent waste. Learn how Legion is helping enterprises solve the SOC talent management crisis.

At Legion, we spend as much time thinking about how we build as we do about what we build. Our engineering culture shapes every decision, every feature, and every customer interaction.
This isn’t a manifesto or a slide in a company deck. It’s a candid look at how our team actually works today, what we care about, and the kind of engineers who tend to thrive here.
We build around four core ideas: Trust, Speed, Customer Obsession, and Curiosity. The rest flows from there.
1. High Ownership, Zero Silos
The foundation of engineering at Legion is simple: we trust you, and you own what you build.
We don’t treat engineering like an assembly line. Every engineer here runs the full loop:
- Shaping the problem and the solution
- Designing and implementing backend, frontend, and AI pieces
- Getting features into production
- Watching how customers actually use what you shipped
That level of ownership creates accountability, but it also creates pride. You see the full impact of your work.
However, ownership doesn’t mean you’re on your own. We don’t build in silos. We are a team that constantly supports each other, whether that’s brainstorming a solution, helping a teammate get unblocked, or just acting as a sounding board.
Part of owning your work is bringing the team along with you. It means communicating your plan and ensuring everyone is aligned on how your work fits into the bigger picture. Collaboration isn't just a process here; it's how we succeed. You own the outcome, but you have the whole team behind you.
Trust is what makes this possible. We don’t track hours or measure success by time spent at a desk. People have kids, partners, lives, good days, and off days. What matters is that we deliver great work and move the product forward. How you organize your time to do that is up to you.
2. Speed Wins (And Responsiveness Matters)
We care a lot about speed, but not the chaotic, “everything is a fire drill” version.
Speed for us means short feedback loops, small and frequent releases, and fixing issues quickly when they appear.
When a customer hits a bug or something breaks, that becomes our priority. We stop, understand the problem, fix it, and close the loop. A quick, thoughtful fix often does more to build trust than a big new feature.
On the feature side, we favor progress over perfection. We’d rather ship a smaller version this week, watch how customers react, and iterate, rather than spend months polishing something in isolation.
Speed doesn’t mean cutting corners. It means learning fast and moving forward with intention. If you like seeing your work in production quickly, and you’re comfortable with the responsibility that comes with that, you’ll fit in well.
3. Customer-Obsessed: Building What They Actually Need
It’s easy for engineering teams to get lost in the code and forget the human on the other side of the screen. We fight hard against that.
We are obsessed with building features that genuinely help our customers, not just features that are fun to code. To do that, we stay close to them. We make a point of hearing directly from users, not just to fix bugs, but to understand the reality of their work and what they truly need to make it easier.
That direct connection builds empathy. It helps us understand why we are building a feature, not just how to implement it. This ensures we don’t waste cycles building things nobody wants. When you understand the core problem, you build a better product, one that delivers real value from day one.
4. Curiosity: We Build for What’s Next
AI is at the center of everything we do at Legion, and that means working in a landscape that changes every week.
We can’t afford to be comfortable with the tools we used last year. We look for engineers who are genuinely curious, the kind of people who play with new models just to see what they can do.
We proactively invest time in emerging technology, knowing that early experimentation is how we define the next industry standard. If you prefer a job where the tech stack never changes, and the roadmap is set in stone for 18 months, you probably won’t enjoy it here. But if you love the chaos of innovation and figuring out how to apply new tech to real security problems, you’ll fit right in.
So, is this for you?
Ultimately, we are trying to build the kind of team we’d want to work in ourselves.
It’s an environment that tries to balance the energy of collaboration in our Tel Aviv office with the quiet focus needed for deep work at home. We try to keep things simple: we are candid with each other, and we value getting our hands dirty over managing processes.
If you want to be part of a team where you are trusted to own your work and move fast, come talk to us. Let’s build something great together.

VP of R&D Michael Gladishev breaks down how the team works, why curiosity drives everything, and what kind of engineers thrive in a zero-ego, high-ownership environment.

The first publicly documented, large-scale AI-orchestrated cyber-espionage campaign is now out in the open. Anthropic disclosed that threat actors (assessed with high confidence as a Chinese state-sponsored group) misused Claude Code to run the bulk of an intrusion targeting roughly 30 global organizations across tech, finance, chemical manufacturing, and government.
This attack should serve as a wake-up call, not because of what it is, but because of what it enables. The attackers used written scripts and known vulnerabilities, with AI primarily acting as an orchestration and reconnaissance layer; a "script kiddy" rather than a fully autonomous hacker. This is just the start.
In the near future, the capabilities demonstrated here will rapidly accelerate. We can expect to see actual malware that writes itself, finds and exploits vulnerabilities on the fly, and evades defenses in smart, adaptive ways. This shift means that the assumptions guiding SOC teams are changing.
What Actually Happened: The Technical Anatomy
The most critical takeaway from this campaign is not the technology used, but the level of trust the attackers placed in the AI. By trusting the model to carry out complex, multi-stage operations without human intervention, they unlocked significant, scalable capabilities far beyond human tempo.
1. Attackers “Jailbroke” the Model
Claude’s safeguards weren’t broken with a single jailbreak prompt. The actors decomposed malicious tasks into small, plausible “red-team testing” requests. The model believed it was legitimately supporting a pentest workflow. This matters because it shows that attackers don’t need to “break” an LLM. They just need to redirect its context and trust it to complete the mission.
2. AI Performed the Operational Heavy Lifting
The attackers trusted Claude Code to execute the campaign in an agentic chain autonomously:
- Scanning for exposed surfaces
- Enumerating systems and sensitive databases
- Writing and iterating exploit code
- Harvesting credentials and moving laterally
- Packaging and exfiltrating data
Humans stepped in only at a few critical junctures, mainly to validate targets, approve next steps, or correct the agent when it hallucinated. The bulk of the execution was delegated, demonstrating the attackers’ trust in the AI’s consistency and thoroughness.
3. Scale and Tempo Were Beyond Human Patterns
The agent fired thousands of requests. Traditional SOC playbooks and anomaly models assume slower human-driven actions, distinct operator fingerprints, and pauses due to errors or tool switching. Agentic AI has none of those constraints. The campaign demonstrated a tempo and scale that is only possible when the human operator takes a massive step back and trusts the machine to work at machine speed.
4. Anthropic Detected It and Shut It Down
Anthropic’s logs flagged abnormal usage patterns, disabled accounts, alerted impacted organizations, worked with governments, and released a technical breakdown of how the AI was misused.

The Defender’s Mandate: Adopt and Trust Defensive AI
Attackers have already made the mental pivot, treating AI as a trusted, high-velocity force multiplier for offense. Defenders must meet this shift head-on. If you don't adopt defensive AI, you are falling behind adversaries who already have.
Defenders must further adopt AI and trust it to carry out workflows where it has a decisive advantage: consistency, thoroughness, speed, and scale.
1. Attack Velocity Requires Machine Speed Defense
When an agent can operate at 50–200x human tempo, your detection assumptions rot fast. SOC teams need to treat AI-driven intrusion patterns as high-frequency anomalies, not human-like sequences.
2. Trust AI for High-Volume, Deterministic Workflows
Existing detection pipelines tuned on human patterns will miss sub-second sequential operations, machine-generated payload variants, and coordinated micro-actions. Agentic workloads look more like automation platforms than human operators.
Defenders need to accept the uncomfortable reality that manual triage for these types of intrusions is pointless. You need systems that can sift through massive alert loads, isolate and contain suspicious agentic behavior as it unfolds.
This is where the defense’s trust must be applied. Only the genuinely complex cases should ever reach a human. The SOC must delegate and trust AI to handle triage, investigation, and response with machine-like consistency.
3. “AI vs. AI” is No Longer Theoretical
Attackers have already made the mental pivot: AI is a force multiplier for offense today. Defenders need to accept the same reality. And Anthropic said this out loud in their conclusion:
“We advise security teams to experiment with applying AI for defense in areas like SOC automation, threat detection, vulnerability assessment, and incident response.”
That’s the part most vendors avoid saying publicly, because it commits them to a position. If you don’t adopt defensive AI, you’re falling behind adversaries who already have.
Where SOC Teams Should Act Now
Build Detection for Agentic Behaviors
Start by strengthening detection around behaviors that simply don’t look human. Agentic intrusions move at a pace and rhythm that operators can’t match: rapid-fire request chains, automated tool-hopping, endless exploit-generation loops, and bursty enumeration that sweeps entire environments in seconds. Even lateral movement takes on a mechanical cadence with no hesitation.
These patterns stand out once you train your systems to look for them, but they won’t surface through traditional detection tuned for human adversaries.
Make AI a Core Strategy, Not an Experiment
Start thinking of adopting AI to fight specific offensive AI use cases, whilst keeping your human SOC on its routine.
Defenders have to meet this shift head-on and start using AI against the very tactics it enables. The volume and velocity of these intrusions make manual triage pointless.
You need systems that can sift through massive alert loads, isolate and contain suspicious agentic behavior as it unfolds, generate and evaluate countermeasures on the fly, and digest massive log streams without slowing down. Only the genuinely complex cases should ever reach a human. This isn’t aspirational thinking; attackers have already proven the model works.
Key Takeaway
For SOC teams, the takeaway is that defense has to evolve at the same pace as offense. That means treating AI as a core operational capability inside the SOC, not an experiment or a novelty.
The Defender’s AI Mandate: Trust AI to handle tasks where it excels: consistency, thoroughness, and scale.
The Defender’s AI Goal: Delegate volume and noise to defensive AI agents, freeing human analysts to focus only on genuinely complex, high-confidence threats that require strategic human judgment.
Legion Security will continue publishing analysis, defensive patterns, and applied research in this space. If you want a deeper dive into detection signatures or how to operationalize defensive AI safely, just say the word.

The Anthropic AI espionage case proves attackers trust autonomous agents. To counter machine-speed threats, SOCs must adopt and trust AI to handle 90% of the defense workload.
Every time a major cyber crisis hits, I feel a familiar frustration and, honestly, anger knowing what’s about to happen inside hundreds of SOCs around the world.
Remember Log4Shell? A few weeks before Christmas, everything went off the rails.
Dozens of analysts and managers are thrown into chaos, scrambling to figure out what’s happening. Long nights, endless meetings, and the exhausting grind of trying to understand what to look for, where to look, and how bad it really is.
I’ve been there: as an analyst, shift lead, SOC Manager, IR Manager, and Head of SecOps. I know exactly how painful those hours are: trying to identify, scope, and contain what’s already been compromised while worrying about what’s coming next.
Key Point #1: Define the Right Steps, Fast
The first thing that matters in any crisis is speed and clarity.
You need to define, immediately, what must happen right now. What are the concrete steps your SOC needs to take to identify and assess evidence of compromise?
At the same time, you need to establish new monitoring systems. New detections that focus on this specific event and its potential evolution, regardless of whether the initial attack was successful or not.
And this is where many SOCs lose time. Too many meetings, too many voices, too much coordination before anyone actually acts. Hours or even days are wasted before a single useful query runs.
Technology continues to evolve to assist in situations like this, so teams should adopt responsibly designed technology that helps augment their capabilities to solve these problems.
This is where the AI SOC changes the game. It can instantly outline and execute those actions, kicking off investigations and monitoring while the team gets aligned.
Key Point #2: Keep the SOC Running Without Breaking the Team
Once the plan is clear, the real challenge begins: keeping up the pace.
Crises can stretch on for days or weeks. You can’t expect analysts to run at full speed forever.
AI SOC can scale these long stretches without completely burning out your teams. It can continuously carry a heavy load, running searches, correlating data, enriching alerts, and maintaining new detection logic. That frees your analysts to focus on core operations, while a small group oversees and validates what the AI produces.
The result: no burnout, no confusion, no collapse of regular SOC operations.
The Shift That Gives Me Hope
For years, technology in the SOC has been reactive. New tools are introduced to solve the last problem. We add dashboards, alerts, and integrations. All of it helps, but it often adds more noise than clarity.
What has been missing is a strategic layer. Systems that understand context, support decisions, and help teams stay focused when everything starts to go wrong.
This new approach is not about automation for its own sake. It is about building a SOC that can think and act in parallel: one part manages daily operations, while the other switches into crisis mode without losing rhythm.
When that balance is right, speed does not come at the expense of clarity, and no one burns out trying to keep up. The technology becomes a stabilizer instead of a stress multiplier.
You move faster. You stay operational. Your people stay sharp.
That is what gives me hope. Because when the next big breach hits, we do not have to relive the same painful cycle.
We can respond with precision, discipline, and confidence, not panic.

Inside a breach, chaos hits fast. Learn more about the reality of crisis response and how rethinking technology and workflow can keep teams faster, clearer, and human.
On August 9, 2025, F5 detected that a “highly sophisticated nation-state threat actor” maintained long-term, persistent access to parts of F5’s internal network (development, engineering, and knowledge management. (ref: Rapid7/Tenable via The Hacker News)
The actor exfiltrated files from F5’s environment, including portions of the BIG-IP source code, internal data on vulnerabilities, and configuration/implementation details for a small subset of F5 customers. The breach gives adversaries the ability to identify or weaponize vulnerabilities in F5 products before general detection or patching cycles. CISA issued Emergency Directive ED 26-01, calling this an imminent threat to networks running F5 devices.
While F5 reports no evidence yet of active exploitation of undisclosed vulnerabilities or supply-chain tampering, the latent risk is very high.
Why This Matters to the SOC
Devices such as BIG-IP (and related F5 appliances/software) sit at high-value network chokepoints, including load balancing, application delivery, VPN/Edge access, and WAF. A successful exploit here can yield broad lateral reach.
The attacker now has access to source code and internal vulnerability documentation, which dramatically reduces the time and effort required for adversaries to craft bespoke zero-day exploits. Because many organisations might delay patching or have externally exposed management interfaces for F5 devices, the window for exploitation is widened.
Even though F5 says there is no evidence yet of the software build or release pipeline being tampered with, you must assume adversaries could exploit this vector in the future.
Key Assets/Systems to Focus On
Alerts/Monitoring: What to Set Up Immediately
Here are recommended alerts and monitoring rules to implement. Depending on your toolset (SIEM, EDR, NDR, device logs), tailor accordingly.
Threat-Hunting Scenarios
Recommended Immediate Steps for SOC / IR Teams
Key Intelligence Sources
- F5’s own Security Notice (KB K000154696) covering details of the incident
- CISA ED 26-01 and associated advisory for federal agencies (applicable for private sector)
- Vendor advisories & CVE list from F5 (October 2025 Quarterly Security Notification) containing patched vulnerabilities
- Threat-intelligence vendor blogs, such as Rapid7, for IOCs and detection rule updates
Takeaways
The F5 breach is more than a vendor incident. It signals a major change in how capable and prepared nation-state actors have become. By stealing source code and internal vulnerability data, attackers have gained deep insight into how F5 products are built and secured. They no longer need to spend time discovering weaknesses; they can start exploiting them.
Every unpatched or misconfigured F5 device should now be viewed as a potential target. This breach shows how critical it is to treat infrastructure software as part of your attack surface. Assume adversaries understand your systems as well as you do, if not better.
Over the next month, your focus should be clear:
- Build complete visibility into every F5 device and interface in your network.
- Isolate management access and enforce strict authentication.
- Patch aggressively and verify every update.
- Monitor continuously for configuration changes or unusual traffic.
- Hunt actively for early indicators of compromise.
This breach is a warning. Acting now, with urgency and precision, is the difference between staying ahead of that wave.

The August 2025 F5 breach exposed BIG-IP source code and internal vulnerability data, giving attackers a roadmap to future exploits. Learn how SOC teams can identify exposure, secure management interfaces, patch fast, and hunt for early compromise indicators before adversaries strike.
The AI industry is heading into an agent-driven future, and three protocols are emerging as the plumbing for AI: Anthropic's Model Context Protocol (MCP), Google's Agent-to-Agent (A2A) protocol, and the newly announced Agent Payments Protocol (AP2). Each is critical for AI infrastructure, but as we've learned repeatedly in cybersecurity, convenience and security rarely come hand in hand.
Having analyzed these protocols from both technical implementation and security perspectives, the picture that emerges is both promising and deeply concerning. We're building the interstate highway system for AI agents, but we're doing it without proper guardrails, traffic controls, or even basic security checkpoints.
The Protocol Trinity: Different Problems, Converging Solutions
Model Context Protocol (MCP): The Universal Connector
MCP functions as a standardized bridge between AI models and external systems through a client-server architecture. MCP clients (embedded in applications like Claude Desktop, Cursor IDE, or custom applications) communicate with MCP servers that expose specific capabilities through a JSON-RPC-based protocol over stdio, SSE, or WebSocket transports.
In layman’s terms, it is essentially a universal connector that enables AI systems to communicate consistently with other software or databases. Apps use an MCP “client” to send requests to an MCP “server,” which performs specific actions in response.
Visual Representation:
Technical Architecture:
1{
2 "jsonrpc": "2.0",
3 "method": "tools/call",
4 "params": {
5 "name": "database_query",
6 "arguments": {
7 "query": "SELECT * FROM users WHERE department = 'engineering'",
8 "connection": "primary"
9 }
10 },
11 "id": "call_123"
12}
13
Scenario: Automated Threat Investigation and Response
Context: A SOC team wants to speed up the triage of security alerts coming from their SIEM (like Splunk or Chronicle). Instead of analysts manually querying multiple tools, they use MCP as the bridge between their AI assistant and their operational systems.
How MCP Fits In
- MCP Client: The SOC’s AI analyst (say, Legion) is the MCP client. It acts as the interface through which analysts ask questions, such as: “Show me the last 10 failed logins for this user and correlate with firewall traffic.”
- MCP Server: On the backend, the MCP server exposes connectors to SOC systems, for example:
- Splunk or ELK (for log searches)
- CrowdStrike API (for endpoint data)
- Okta API (for authentication events)
- Jira or ServiceNow (for case creation)
- Each connector is defined as a “tool” in the MCP schema (e.g., query_siem, get_endpoint_status, create_ticket).
Workflow Example: AI Analyst (MCP Client) → MCP Server
method: "tools/call"
params:
name: "query_siem"
arguments:
query: "index=auth failed_login user=jsmith | stats count by src_ip"
The MCP server runs the Splunk query, returns results, and the AI can then call another MCP tool:
name: "get_endpoint_status"
arguments:
host: "192.168.1.22"The AI correlates results, summarizes findings, and can automatically open an incident via:
name: "create_ticket"
arguments:
severity: "High"
summary: "Repeated failed logins detected for jsmith"
Security Considerations
- Credential aggregation risk: One compromised MCP client could expose multiple API keys (SIEM, EDR, etc.).
- Schema poisoning: If an attacker injects malicious JSON schema data, it could alter what the AI interprets or requests.
- Mitigation: Use Docker MCP Gateway interceptors and strict per-tool access scopes.
Agent-to-Agent (A2A): The Coordination Protocol
A2A enables autonomous agents to discover and communicate through standardized Agent Cards served over HTTPS and JSON-RPC communication patterns. The protocol supports three communication models: request/response with polling, Server-Sent Events for real-time updates, and push notifications for asynchronous operations.
Basically, A2A lets AI agents automatically find, connect, and collaborate with each other safely and efficiently, no humans in the loop.
Visual Representation:
Technical Protocol Structure:
{
"agent_id": "procurement-agent-v2.1",
"version": "2.1.0",
"skills": [
{
"name": "vendor_evaluation",
"description": "Analyze vendor proposals against procurement criteria",
"parameters": {
"criteria": {"type": "object"},
"proposals": {"type": "array"}
}
}
],
"communication_modes": ["request_response", "sse", "push"],
"security_requirements": {
"authentication": "oauth2",
"encryption": "tls_1.3_minimum"
}
}
Scenario: Automated Incident Collaboration Between Security Agents
Context: Your SOC runs multiple specialized AI agents: one monitors network traffic, another investigates suspicious users, another handles remediation actions (like isolating a device or resetting credentials). A2A provides the common protocol that lets these agents talk to each other directly, securely, automatically, and in real time.
How It Works in Practice
- Agent Discovery via Agent Cards
- Each SOC agent publishes an Agent Card, a digital profile that says:
- “I’m a Threat Detection Agent.”
- “I can analyze network logs and spot anomalies.”
- “Here’s how to contact me securely.”
- The A2A system keeps these cards available over HTTPS, so other agents can find and verify them.
- Each SOC agent publishes an Agent Card, a digital profile that says:
Example:
{
"agent_id": "threat-detector-v2",
"skills": ["network_log_analysis", "malware_pattern_detection"],
"authentication": "oauth2",
"encryption": "tls_1.3"
}
- Agent-to-Agent Workflow
- The Threat Detection Agent flags unusual outbound traffic from a server.
- It sends a message via A2A to the Endpoint Response Agent, saying:
“Investigate host server-22 for potential C2 beacon activity.” - The Endpoint Agent checks EDR data and replies with a summary or alert.
- Simultaneously, it notifies the Incident Coordination Agent to open a ticket in ServiceNow.
- Communication Models in Action
- Request/Response: Threat Detector asks → Endpoint Agent replies.
- Server-Sent Events: Endpoint Agent streams live scan results back.
- Push Notification: Incident Coordinator gets notified once a full report is ready.
Critical Security Concerns
- Agent Card Spoofing: Malicious agents advertising false capabilities through manipulated HTTPS-served metadata
- Capability Hijacking: Compromised agents with inflated skill advertisements capturing disproportionate task assignments
- Communication Channel Attacks: Man-in-the-middle and session hijacking on agent-to-agent communications
- Workflow Injection: Malicious agents inserting unauthorized tasks into legitimate multi-agent workflows
Agent Payments Protocol (AP2): The Commerce Enabler
AP2 extends A2A with cryptographically-signed Verifiable Digital Credentials (VDCs) to enable autonomous financial transactions. The protocol implements a two-stage mandate system using ECDSA signatures and supports multiple payment rails, including traditional card networks, real-time payment systems, and blockchain-based settlements.
Basically, AP2 lets AI agents make trusted, auditable payments automatically without a human typing in a credit card number.
Visual Representation:
Technical Mandate Structure:
{
"intent_mandate": {
"mandate_id": "im_7f8e9d2a1b3c4f5e",
"user_id": "enterprise_user_12345",
"conditions": {
"item_category": "cloud_services",
"max_amount": {"value": 5000, "currency": "USD"},
"vendor_whitelist": ["aws", "gcp", "azure"],
"approval_threshold": {"value": 1000, "requires_human": true}
},
"signature": "304502210089abc...",
"timestamp": "2025-01-15T10:30:00Z",
"expires_at": "2025-01-16T10:30:00Z"
},
"cart_mandate": {
"mandate_id": "cm_8g9h0e3b2c4d5f6g",
"references_intent": "im_7f8e9d2a1b3c4f5e",
"line_items": [
{
"vendor": "aws",
"service": "ec2_reserved_instances",
"amount": {"value": 3500, "currency": "USD"},
"contract_terms": "1_year_reserved"
}
],
"payment_method": "corporate_card_ending_1234",
"signature": "3046022100f4def...",
"execution_timestamp": "2025-01-15T11:45:00Z"
}
}
Scenario: Secure Autonomous Cloud Resource Payments
Context: Your company’s AI agents automatically manage cloud infrastructure — spinning up or shutting down virtual machines based on workload. To do that, they sometimes need to authorize and execute payments (e.g., buying more compute time or storage). AP2 allows those agents to make these payments automatically — but with strong security guardrails.
How It Works
- Step 1 – Intent Mandate (the plan)
- The agent first creates an Intent Mandate describing what it wants to do.
Example: “Purchase $2,000 worth of AWS compute credits for Project Orion.” - This mandate includes:
- Vendor whitelist (AWS only)
- Spending cap ($5,000 max)
- Expiry time (valid for 24 hours)
- Digital signature (ECDSA) proving it came from an authorized agent
- A human or rule engine reviews this intent before any money moves.
- The agent first creates an Intent Mandate describing what it wants to do.
- Step 2 – Cart Mandate (the action)
- Once the intent is approved, the agent generates a Cart Mandate — the actual payment order.
- It references the original intent, ensuring the details match (no one changed the vendor or amount).
- This mandate is also cryptographically signed and executed via a secure payment rail (e.g., corporate card API or blockchain payment).
- Security Enforcement During Payment
- Independent validator checks that:
- The intent and cart match exactly.
- The agent’s digital credential is still valid (hasn’t been revoked).
- The payment doesn’t exceed limits or policy.
- Real-time monitoring watches for anomalies:
- Multiple large payments in short time windows
- Changes to vendor lists
- Repeated failed authorizations
- Independent validator checks that:
- Audit & Traceability
- Every mandate (intent and payment) is stored with its cryptographic proof.
- Auditors can later verify every transaction end-to-end
Security Benefits
Cryptographic Signatures: Ensures that only verified agents can create or authorize payments.
Two-Stage Mandate System: Prevents “prompt injection” or unauthorized payments by requiring two consistent steps (intent → execution).
Vendor Whitelisting & Spending Caps: Limits the blast radius of any compromise.
Cross-Protocol Correlation: AP2 can check MCP/A2A activity logs before allowing a transaction — ensuring payment actions match legitimate workflows.
Immutable Audit Trail: Every payment is traceable, signed, and non-repudiable.
Without these controls, a single compromised AI could:
- Create fake purchase requests (“buy 1000 GPUs from an attacker’s vendor”)
- Manipulate prices between intent and payment
- Execute valid-looking, cryptographically signed frauds
That’s why AP2’s mandate validation and signature chaining are essential. They make it nearly impossible for a rogue or manipulated agent to spend money unchecked.
Architectural Convergence
What's fascinating is how these protocols complement each other in ways that suggest a coordinated vision for agentic infrastructure:
- MCP provides vertical integration (agent-to-tool)
- A2A enables horizontal integration (agent-to-agent)
- AP2 adds transactional capability (agent-to-commerce)
The intended architecture is clear: an AI agent uses MCP to access your calendar and email, A2A to coordinate with specialized booking agents, and AP2 to complete transactions autonomously. It's elegant in theory, but the security implications are staggering.
Implementation Recommendations: Protocol-Specific Security Controls
MCP Security Implementation
Mandatory Tool Validation Framework: Deploy comprehensive MCP server scanning that extends beyond basic description fields:
Static Analysis Requirements:
- Scan all tool metadata (names, types, defaults, enums)
- Source code analysis for dynamic output generation logic
- Linguistic pattern detection for embedded prompts
- Schema structure validation against known-good templates
Runtime Protection with Docker MCP Gateway: Implement Docker's MCP Gateway interceptors for surgical attack prevention:
# Example: Repository isolation interceptor
def github_repository_interceptor(request):
if request.tool == 'github':
session_repo = get_session_repo()
if session_repo and request.repo != session_repo:
raise SecurityError("Cross-repository access blocked")
return request
Continuous Behavior Monitoring: Deploy real-time MCP activity analysis:
- Tool call frequency analysis to detect automated attacks
- Data access pattern monitoring for unusual correlation activities
- Output analysis for prompt injection indicators
- Cross-tool interaction mapping to identify attack chains
A2A Security Architecture
Agent Authentication Infrastructure: Implement certificate-based mutual authentication for all agent communications:
Agent Registration Process:
- Certificate generation with organizational root CA
- Agent Card cryptographic signing with private key
- Capability verification through controlled testing
- Regular certificate rotation (30-day maximum)
Communication Security Controls: Establish secure communication channels with comprehensive auditing:
Required A2A Security Headers:
- X-Agent-ID: Cryptographically verified agent identifier
- X-Capability-Hash: Tamper-evident capability fingerprint
- X-Session-Token: Short-lived session authentication
- X-Audit-ID: Immutable audit trail identifier
Agent Capability Verification System: Never trust advertised capabilities without independent verification:
class AgentCapabilityVerifier:
def verify_agent(self, agent_card):
test_results = self.sandbox_test(agent_card.capabilities)
capability_match = self.validate_capabilities(test_results)
return self.issue_capability_certificate(capability_match)
AP2 Security Implementation
Mandate Validation Infrastructure: Implement independent mandate validation outside AI agent context:
Multi-Stage Validation Process:
- AI-generated Intent Mandate creation
- Independent rule-engine validation of mandate logic
- Human approval workflow for high-value transactions
- Cryptographic signing with organizational keys
- Real-time transaction monitoring against mandate parameters
Payment Transaction Monitoring: Deploy comprehensive payment pattern analysis:
class AP2TransactionMonitor:
def analyze_payment(self, mandate, transaction):
risk_score = self.calculate_risk_score(
user_history=self.get_user_patterns(),
agent_behavior=self.get_agent_patterns(),
transaction_details=transaction,
mandate_consistency=self.validate_mandate(mandate)
)
if risk_score > THRESHOLD:
return self.trigger_additional_verification()
Cross-Protocol Security Integration: Deploy unified monitoring across MCP, A2A, and AP2:
class CrossProtocolSecurityOrchestrator:
def monitor_agent_workflow(self, workflow_id):
mcp_activity = self.monitor_mcp_calls(workflow_id)
a2a_communications = self.monitor_agent_interactions(workflow_id)
ap2_transactions = self.monitor_payment_activity(workflow_id)
# Correlate activities across protocols
risk_assessment = self.correlate_cross_protocol_activity(
mcp_activity, a2a_communications, ap2_transactions
)
if risk_assessment.is_suspicious():
self.trigger_workflow_isolation(workflow_id)
The Broader IAM Implications
These protocols represent a fundamental shift in identity and access management. We're transitioning from human-centric IAM to agent-centric IAM, and our current security models are insufficient for this shift.
Derived Credentials will become essential as agents need to authenticate not just to services, but to each other. AP2's mandate system is an early attempt at this, but we need comprehensive frameworks for agent identity lifecycle management.
Contextual Authorization must replace simple role-based access control. Agents will need fine-grained permissions that adapt to context, user intent, and risk levels.
Audit Trails become exponentially more complex when multiple agents coordinate across multiple systems to complete user requests. We need new forensic capabilities for multi-agent investigations.
Bottom Line: The Infrastructure We Build Today Shapes Tomorrow's Security Landscape
After spending months analyzing these protocols and watching the industry rush toward agentic implementation, I keep coming back to a fundamental truth: we're not just deploying new technologies. We're architecting the nervous system for autonomous digital commerce and operations.
MCP, A2A, and AP2 aren't just convenient APIs or communication standards. They represent the foundational infrastructure that will determine whether the agentic economy becomes a productivity revolution or a security catastrophe. The decisions we make about implementing these protocols today will echo through decades of digital infrastructure.
The security vulnerabilities I've outlined aren't theoretical concerns, but active attack vectors being demonstrated by researchers right now. Tool poisoning attacks against MCP are working in production environments. A2A agent spoofing is trivial to execute. AP2's mandate system can be subverted through the same prompt injection techniques we've known about for years.
Here's what gives me confidence: the collaborative approach emerging around these protocols. When Google open-sources A2A with 60+ industry partners, when Docker develops security interceptors for MCP, when researchers rapidly disclose vulnerabilities and the community responds with patches. This is how robust infrastructure gets built.
Explore the security analysis of AI protocols shaping the future of AI. MCP, A2A, and AP2 form the backbone of agentic systems but without strong safeguards, these protocols could expose the next generation of AI infrastructure to serious security risks.

Top Cybersecurity Certifications and When to Get Them
What cybersecurity certifications should I get? It’s a question that stumps even the most experienced experts in cybersecurity, and one that I have been actively trying to figure out on my own (with little to no success).
I’m currently going through the process of training to be a SOC analyst (because… why not). And the #1 problem I’ve faced is figuring out where to start. Most people start off doing what I did. Ask ChatGPT. Go to Google. Sift through Reddit. And it seems that there is no clear answer to this question.
There are so many certifications and courses that it can sometimes feel daunting:
- Do you pay for courses aligned with governing boards like ISC2 and CompTIA?
- Do you go the YouTube route and find free resources?
- Do you go back to school (I’ve seen Western Governors University listed, A LOT)
- Do you go off the beaten path and try more hands-on learning like BTL1 from Security Blue?
To help solve this problem, I enlisted the assistance of some of the world's most respected security professionals and sought their input on the matter. Here you go.
Skylar Lyons (aka csp3r)

If there’s a corner of cybersecurity Skylar hasn’t touched, it’s hard to find. Skylar has spent nearly two decades shaping the way organizations defend themselves. They are currently the CISO at Vannadium, which offers a data infrastructure powered by blockchain / distributed ledger technology (DLT), giving organizations real-time, secure, and tamper-evident data operations.
Skylar’s selections on certifications? CISSP and OSCP.
The CISSP gives you an overview of security as a whole, and the OSCP provides you with the skills to actually write a report. The big problem today is that people can’t articulate how to translate between technical measures and business acumen. This combination gives you both.
Go give Skylar a follow: https://www.linkedin.com/in/csp3r/
Rafal Kitab

I’ve had the opportunity to get to know Rafal briefly after his work on the 2025 AI SOC Market Landscape report with Francis Odum, and it’s safe to say that Rafal is one of the most forward-thinking security professionals I have met. We were supposed to discuss AI SOC for 30 minutes and ended up delving into the details of automations, detections, and the impact of AI on security teams.
Rafal offers a pragmatic and practical perspective on certifications. A few key points he hammers home:
- Knowledge beats certifications, but having certifications with knowledge will get you paid more.
- The most important utility of certs in cybersecurity is helping you get past the HR filter.
- The best certifications for that purpose are a mile wide and an inch deep, as they allow you flexibility and are not too hard to obtain.
CISSP comes to mind as an example. It is not groundbreaking content-wise, but it lays down the basics of many different areas quite well, and the fact that you've got it opens many doors.
His advice on how to plan a certification path for a blue teamer:
Start with something broad, like Security+. Then, grab two intermediate cloud certs. If you can afford it, get GIAC. If you’re five years in, consider getting your CISSP.
Go give Rafal a follow: https://www.linkedin.com/in/rafa%C5%82-kitab-b6881baa/
Dr. Stephen Coston

If this section doesn’t tell you precisely the kind of person Stephen is, I don’t know what will. I sent a simple question to him about his viewpoint on certifications. In return? I had to build a Google sheet outlining all of the fantastic advice he gave: Cybersecurity Certs Recommended by Dr. Stephen Coston
These certifications focus on building a comprehensive AI leadership portfolio, spanning strategy, security, technical fluency, and ethics. Together, these certifications position someone as an executive who can both lead AI adoption and understand its technical and ethical depth.
A significant gap today is the ability for an individual to bridge boardroom strategy, cybersecurity operations, and hands-on generative AI capabilities. These certifications can give you a mix of technical and executive skills to manage teams implementing AI.
Follow Stephen: https://www.linkedin.com/in/dr-stephen-coston
Darwin Salazar

Darwin has been in the security industry for nearly a decade, establishing a reputation as both a practitioner and a security content creator. He’s the author of The Cybersecurity Pulse (which I highly recommend reading if you want to stay current).
When it comes to professional development, Darwin’s certification focus reflects a deeply technical viewpoint. Instead of collecting a broad mix, he zeroed in on certs that sharpen operational expertise:
- CKA (Certified Kubernetes Administrator)
- CKS (Certified Kubernetes Security Specialist)
- Cloud Security Certifications like Microsoft’s AZ-500
This mix signals a focus on hands-on skills in container security, cloud defense, and securing modern infrastructure. This is the kind of technical grounding that keeps content real and battle-tested.
Follow Darwin: https://www.linkedin.com/in/darwin-salazar/
Follow The Cybersecurity Pulse: https://www.cybersecuritypulse.net/
0xdf

I first connected with 0xdf through a mutual follower, and it’s safe to say his technical depth and application of security principles are top-tier. He spent nearly five years as a Cybersecurity Trainer at Hack The Box, helping shape the next generation of security professionals, and today serves as a Member of Technical Staff at Anthropic.
When it comes to certifications, 0xdf takes a holistic view:
- OSCP – still the most recognized by HR and recruiters, but not necessarily the strongest for actual learning. The course materials are thin, and the infamous “try harder” support doesn’t offer much help.
- CPTS (HTB Certified Penetration Testing Specialist) – much higher quality, with a steadily growing reputation. If your goal is learning, this is the better choice.
- SANS / GIAC certifications – excellent for in-person training and hands-on learning, but prohibitively expensive for individuals. If your employer or school will cover the cost, jump at the chance.
His viewpoint is pretty clear in my opinion: go for certs that actually sharpen your skills.
Follow 0xdf: https://www.linkedin.com/in/0xdf/
Follow 0xdf on Gitlab & YouTube: https://0xdf.gitlab.io/ , https://www.youtube.com/@0xdf
Arbnor Mustafa

Quick story: the first time Arbnor and I interacted on LinkedIn, he (respectfully) corrected something I had posted. I DM’d him to thank him, and that’s how our conversation started.
Arbnor is a SOC Team Lead at Sentry, a cybersecurity services company based in Southern Europe. What stands out is that he has a knack for breaking down complex security concepts in a way that resonates with his audience.
When I asked for his thoughts on certifications, his viewpoint was direct:
“A certification is the minimum to deliver a job position. Job seekers should also have blogs, GitHub projects, and at least 3 minor cybersecurity projects that emulate a cyber attack.”
Here’s how he maps certs to career paths:
- CCNA | CCNP → Network Technician / Engineer
- OSCP → Offensive Security Engineer / Analyst
- BTL1 → Defensive Security Engineer / Analyst
- CRTO | CRTL → Red Teamer
- CISSP → CISO / CTO / Team Lead
- CACP → Required to start an internship on the Sentry team
Certifications are the baseline, not the finish line. Real-world projects and demonstrable skills are what set candidates apart.
Follow Arbnor: https://www.linkedin.com/in/arbnor-mustafa-77490a1b8/
Shanief Webb

I’ve been following Shanief Webb for years — going back to when he was a guest on a podcast at a previous job. His career reads like a tour of some of the world’s most advanced tech companies: Google, Slack, Dropbox, Okta, Meta, and now Headspace, where he continues to bring deep expertise in security engineering.
When I asked him for his take on certifications, his response was refreshingly honest:
“I don’t have a ‘best certifications’ list. I’ve always viewed them as a means to an end, not the end itself. The right certification depends entirely on your career goals. They might get you an interview, but it’s your knowledge and — more importantly — your experience that gets you the job.”
Instead of rattling off certs, Shanief offers a framework for anyone asking how to approach them:
- Define Your Destination – Be specific: Cloud Security Engineer? Web App Pentester? GRC Analyst? Don’t just say “cybersecurity.”
- Map the Requirements – Study 5–10 job postings for that role at companies you respect; identify the common skills, tools, and qualifications.
- Identify Your Gaps – Compare those requirements against your own experience. The gaps become your personal learning plan.
- Choose Your Tool – Only then consider certifications — if they help close those gaps and consistently appear in job postings.
Some of today’s most critical skills, such as practical threat modeling and security investigation fundamentals, lack a formal certification path. Those still come from hands-on experience.
I’ll boil down his advice into what I interpret it to be.
Let ambition drive your learning. Be intentional, focus on the role you want, and acquire the skills (and certifications, when applicable) that will get you there. Collecting credentials for their own sake won’t move the needle.
Follow Shanief: https://linkedin.com/in/shanief
Jason Rebholz

Jason is another friendly connection from a previous role, and he brings a different perspective to the discussion about certifications. His background spans nearly every corner of security leadership, encompassing roles such as leading in-house incident response teams, running IR consulting groups, serving as a CISO, and founding multiple security companies. He doesn’t just work in cybersecurity; he speaks about it, writes about it, and lives it daily.
When asked about certifications, Jason’s recommendation stood out:
“In my research, the Google Cybersecurity Professional Certificate has been one of the more robust trainings available. It gives a baseline understanding of fundamental networking and systems concepts that accelerate your grasp of security risks. It’s broad enough to expose you to different areas of security, but deep enough to move past just buzzwords.”
It’s the main certification he recommends to people looking to enter cybersecurity with practical, structured, and accessible content, while building real foundational knowledge.
Follow Jason: https://www.linkedin.com/in/jrebholz/
Follow his newsletter: https://weekendbyte.com/
Filip Stojkovski
.avif)
Filip Stojkovski is a well-respected member of the security industry and active contributor the SecOps space. Currently, he is a Staff Security Engineer at Snyk and the Founder of SecOps Unpacked. His approach blends hands-on technical expertise with a clear understanding of how governance and compliance fit into the bigger picture.
Filip organizes certifications into three buckets:
- The "Hands-On" Stuff
- Focus: Practical, technical skills you’ll use daily in security operations.
- Examples: SANS, OSCP, TryHackMe.
- The "Compliance/Audit" Stuff
- Focus: Governance, risk, and compliance—popular with consultants and auditors.
- Examples: CISSP, CISM, CASP+, CISA.
- The "Foundational" Stuff
- Focus: Proving baseline knowledge and fundamentals, often for those starting out.
- Examples: CompTIA Security+, CEH, CCNA.
The certifications that helped him most include:
- SANS DFIR/GCFA (Forensics)
- SANS 599 (Purple Team)
- SANS 578 (Threat Intelligence)
And for those who want a great free resource, his favorite is this Google Cloud course: Google Cloud Skills Boost: Security in Google Cloud
Go follow Filip: https://www.linkedin.com/in/filipstojkovski/
Subscribe to his content: https://secops-unpacked.ai/
Categories of Certifications
Navigating the world of cybersecurity certifications can seem complex, but understanding the main categories can help you forge a clear path. As we've seen from the insights of leading security professionals, certifications generally fall into four key groups:
- Broad/Foundational: a wide overview of essential cybersecurity concepts that are often crucial for getting past initial HR filters, setting a strong base for further specialization.
- Hands-On/Offensive: sharpen your technical skills, whether it's through penetration testing, red teaming, or blue team operations
- Cloud & Container Security: vendor-agnostic options like GIAC and vendor-specific like CKA/CKS. These ensure you have the skills to protect modern, dynamic environments.
- Leadership & Strategy: leadership, strategy, and AI-focused prepare you to bridge technical operations with business objectives and manage teams
Ultimately, the right certification path aligns with your specific career goals and helps you acquire the knowledge and experience to excel in cyber.

What are the top cybersecurity certifications, and which should I get? To help solve this problem, I enlisted the assistance of some of the world's most respected security professionals.